원글 페이지 : 바로가기
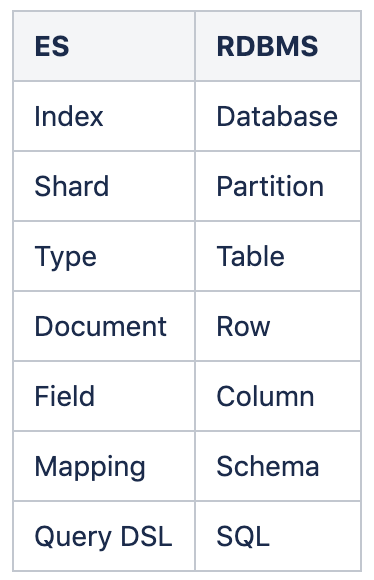
Elastic search – Elastic search란? 보통 검색 기능을 구현할 때에는 Like 연산자를 사용하여 특정 검색 키워드를 입력하면 해당 키워드를 포함하거나 일치하는 데이터를 찾아내지만 데이터를 행(row) 단위로 한 줄씩 저장시키게 되고 like검색을 사용하게 되면, 테이블의 첫 행부터 마지막 행까지 전체 데이터를 탐색하면서 데이터를 찾아내야해서 탐색해야 될 데이터들이 많아지게 되면 시간도 오래 걸리고 데이터를 모두 읽어야 하기 때문에 속도가 더 느릴 수 있다. 이 때에 효율을 개선하기 위해서 elastic search(ES)를 사용할 수 있다. – Elastic search는 어떤 특정한 정보를 찾으려 할 때 키워드를 중심으로 저장되기 때문에 빠른 검색이 가능하다 – Elastic search에서 사용되는 자료 구조 ES의 자료구조(출처: https://jaemunbro.medium.com/elastic-search-%EA%B8%B0%EC%B4%88-%EC%8A%A4%ED%84%B0%EB%94%94-ff01870094f0) Index 데이터 저장 공간 하나의 물리 노드에 여러개 논리 인덱스 생성 하나의 인덱스가 여러 노드에 분산 저장 (M:N) Shard 색인된 문서는 하나의 인덱스 — 인덱스 내부에 색인된 데이터는 여러개의 파티션으로 나뉘어 구성됨. (파티션 = 샤드) Type 인덱스의 논리적 구조 6.1부터 인덱스당 하나의 타입만 설정 가능(6.0 이하에서는 music 인덱스에서 rock, pop등 장르별로 분리하는데 타입을 사용할 수 있었음) Document 데이터가 저장되는 최소 단위 JSON 포맷으로 저장 DB의 Row에 대응됨. Field 문서를 구성하기 위한 속성 DB의 컬럼과 비교할 수 있음 하나의 필드는 목적에 따라 다수의 데이터 타입을 가질 수 있음 Mapping 문서의 필드, 필드 속성을 정의하고 그에 따른 색인 방법을 정의하는 프로세스 스키마 정의 프로세스라고 보면 된다. – Elastic search는 REST API를 통해 데이터 조작을 지원한다 (GET, PUT, POST, DELETE, HEAD(인덱스 정보 확인) – Elasticsearch는 데이터를 저장할 때 역 인덱스(inverted index) 라는 구조로 만들어 데이터를 저장 ES의 inverted index(출처: https://velog.io/@snghyun331/Elasticsearch-Logstash%EB%A5%BC-%ED%99%9C%EC%9A%A9%ED%95%9C-%EA%B2%80%EC%83%89-%ED%92%88%EC%A7%88-%EA%B0%9C%EC%84%A0%EA%B8%B0Nestjs#:~:text=Elasticsearch%EB%8A%94%20must%2C%20must_all%2C%20term,%EC%9E%88%EB%8A%94%20%EA%B2%83%EB%8F%84%20%ED%81%B0%20%EC%9E%A5%EC%A0%90%EC%9D%B4%EB%8B%A4.) – 특정 문장의 단어를 분석하여 key-value 형식의 JSON으로 변환하여 저장(이와 같이 저장된 문서를 document라고 함) – ES의 장점 : 실시간 검색 및 분석: 엘라스틱서치는 대량의 데이터를 실시간으로 검색하고 분석할 수 있습니다. 이는 로그 분석, 모니터링, 데이터 시각화 등 다양한 분야에 유용합니다. 확장성: 분산 시스템을 기반으로 하여 대량의 데이터를 처리할 수 있습니다. 필요에 따라 노드를 추가하여 수평적 확장이 가능합니다. 유연한 데이터 스키마: 다양한 데이터 형식을 지원하며, 데이터 스키마가 동적으로 변화할 수 있습니다. 이는 비정형 데이터를 처리하는 데 유리합니다. 강력한 검색 기능: must, must_all, term, match, match_phrase 등의 다양한 쿼리를 활용과 필터링을 지원하여 다양한 검색 요구사항을 충족시킬 수 있습니다. 또한, 자연어 처리 기능을 통해 사용자 친화적인 검색을 구현할 수 있습니다. 광범위한 생태계: 엘라스틱서치는 키바나(Kibana), 로그스태시(Logstash), 비츠(Beats) 등과 같은 도구들과 통합되어 강력한 데이터 수집, 분석, 시각화 기능을 제공합니다. – ES의 단점 : 운영 복잡성: 클러스터 관리, 데이터 노드의 균형 조정, 백업 및 복구 등 운영 측면에서 복잡성이 높습니다. 전문적인 지식이 필요할 수 있습니다. 리소스 요구량: 대규모 데이터 처리를 위해 많은 하드웨어 리소스가 필요합니다. 특히 메모리와 스토리지의 요구량이 높을 수 있습니다. 데이터 일관성 문제: 분산 시스템의 특성상 일관성(consistency) 문제를 처리하는 데 어려움이 있을 수 있습니다. 데이터 복제와 분할 시점에 따라 일관성 문제가 발생할 수 있습니다. 학습 곡선: 엘라스틱서치의 다양한 기능과 설정을 이해하고 활용하는 데 시간이 걸릴 수 있습니다. 이는 학습 곡선이 가파르다는 것을 의미합니다. 보안 문제: 기본 설정으로는 보안이 강화되어 있지 않습니다. 따라서 보안을 강화하기 위해 추가적인 설정과 관리가 필요합니다.